|
|
11 months ago | |
|---|---|---|
| .. | ||
| audit | 11 months ago | |
| resources | 11 months ago | |
| README.md | 11 months ago | |
README.md
CRUD Master Py
Instructions
APIs are a very common and convenient way to deploy services in a modular way. In this exercise we will create a simple microservices infrastructure, having an API Gateway connected to two other services. Those two services will in turn get data from two distinct databases. The communication between services will be done by using HTTP and message queuing systems. All those services will be in turn encapsulated in different virtual machines.
General overview
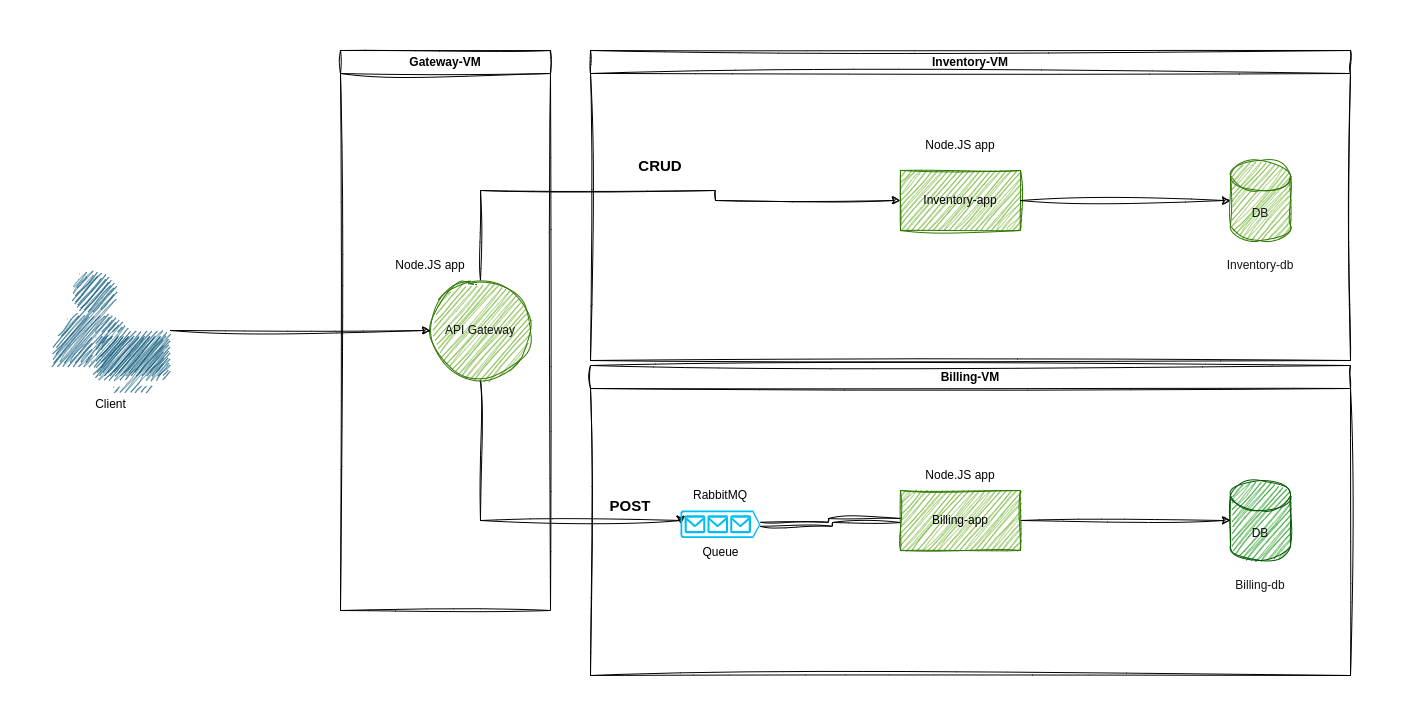
We will set up a movie streaming platform, where one API (inventory) will
have information on the movies available and another one (billing) will
process the payments.
The API gateway will communicate in HTTP with the inventory service and using
RabbitMQ for billing service.
In this exercise you will need to install Python3 (with Flask, SQLAlchemy and other packages), PostgreSQL, RabbitMQ, Postman, VirtualBox and Vagrant.
While it may seem overwhelming at first, there are a lot of resources available both on official website and on community blogs about setting up those tools. Also, the specific configuration details may change from platform to platform so don't hesitate to play around with it and be sure everything is installed correctly before to move on.
API 1: Inventory
Definition of the Inventory API
This API will be a CRUD (Create, Read, Update, Delete) RESTful API. It will use a PostgreSQL database. It will provide information about the movies present in the inventory and allow users to do basic operations on it.
A common way to do so is to use Flask which is a popular Python web framework. We will couple it with SQLAlchemy, an ORM which will abstract and simplify the interactions between our API and the database.
Here are the endpoints with the possible HTTP requests:
/api/movies: GET, POST, DELETE/api/movies/:id: GET, PUT, DELETE
Some details about each one of them:
-
GET /api/moviesretrieve all the movies. -
GET /api/movies?title=[name]retrieve all the movies withnamein the title. -
POST /api/moviescreate a new product entry. -
DELETE /api/moviesdelete all movies in the database. -
GET /api/movies/:idretrieve a single movie byid. -
PUT /api/movies/:idupdate a single movie byid. -
DELETE /api/movies/:iddelete a single movie byid.
The API should work on http://localhost:8080/.
Defining the Database
For the database we will use PostgreSQL.
The database will be called movies_db.
The movies table will contain the following columns:
id: auto-generated unique identifier.title: the title of the movie.description: the description of the movie.
Testing the Inventory API
In order to test the correctness of your API you should use Postman or a similar tool. You could create one or more tests for every endpoint and then export the configuration, so you will be able to reproduce the tests on different machines easily.
API 2: Billing
Definition of the Inventory API
This API will only receive messages through RabbitMQ, specifically it will
consume messages on the queue billing_queue. The message it receives are
going to be a "stringified" JSON object as in this example:
{
"user_id": "3",
"number_of_items": "5",
"total_amount": "180"
}
It will parse the message and create a new entry in the orders_db database.
It will also acknowledge the RabbitMQ queue that the message has been
processed. When the API is started it will take and process all messages
present in the queue.
Take a look into
pikaPython library for an easy way to interface with RabbitMQ.
Defining the Database
For the database we will use PostgreSQL here as well.
The database will be called orders_db.
The orders table will contain the following columns:
id: auto-generated unique identifier.user_id: the id of the user making the order.number_of_items: the number of items included in the order.total_amount: the total cost of the order.
Testing the Billing API
To test this API here are some steps:
- Send POST orders to the API Gateway (you can use Postman for that).
- When the Billing API is running the orders should appear instantaneously in
the
ordersdatabase. - When the Billing API is not running the queries to the API Gateway should
still return success but the
ordersdatabase won't be updated. - When the Billing API is started again the unfulfilled messages should be
processed and the
ordersdatabase should be updated.
The API Gateway
The Gateway will take care of routing the requests to the appropriate service using the right protocol (it could be HTTP for the Inventory API or RabbitMQ for the Billing API).
Interfacing with Inventory API
The gateway will route all requests to /api/movies at the API 1, without any
need to check the information passed through it. It will return the exact
response received by the API1.
Interfacing with Billing API
The gateway will receive POST requests from api/billing and send a message
using RabbitMQ in a queue called billing_queue. The content of the message
will be the POST request body stringified with JSON.stringify. The Gateway
should be able to send messages to queue even if the API 2 is not running.
When the API2 will be started it should be able to process that message and
send an acknowledgement back.
An example of POST request to
http://[API_GATEWAY_URL]:[API_GATEWAY_PORT]/api/billing/:
{
"user_id": "3",
"number_of_items": "5",
"total_amount": "180"
}
Remember to set up
Content-Type: application/jsonfor the body of the request.
Documenting the API
Good documentation is a very critical feature of every API. By design the APIs are meant for others to use, so there have been very good efforts to create standard and easy to implement ways to document it.
As an introduction to the art of great documentation you must create an OpenAPI documentation file for the API Gateway. There are many different ways to do so, a good start could be using SwaggerHub with at least a meaningful description for each endpoint. Feel free to implement any extra feature as you see fit.
You must also create a
README.mdfile at the root of your project with detailed instructions on how to build and run your infrastructure and which design choices you made to structure it.
Virtual Machines
General overview
You will use VirtualBox and Vagrant to set up three different VMs in order to test the interactions and correctness of responses between your APIs infrastructure.
Vagrant is an open-source software that helps you create and manage virtual machines. With Vagrant, you can create a development environment that is identical to your production environment, which makes it easier to develop, test, and deploy your applications.
Your VMs will be structured as follows:
gateway-vm: This VM will only contain theapi-gateway.inventory-vm: This VM will contain theinventory-appAPI and the databasemovies_db.billing-vm: This VM will contain thebilling-appAPI, databaseordersand RabbitMQ.
Vagrant is designed for development and should not be used in production environments.
Environment variables
To simplify the building process it is a common practice to store useful
variables in a .env file. It will make very easy to modify/update information
like URLs, passwords, users and so on.
Those variables will then be used by Vagrant and passed through the different microservices in order to centralize all the credentials.
Your .env file should contain all the necessary credentials and none of the
microservices should have any credential hard coded in the source code.
For the purpose of this exercise the
.envfile must be included in your repository, though usually in public and production projects the.envfile is never included in repos to avoid sensitive data leaks.
Configuration of the VMs
- You will have a
Vagrantfilewhich will create and start the three VMs. It will import the environment variables and pass them through each API. - You will have a
script/directory which will store all the scripts you may want to run in order to install the necessary tools on each VM. Those scripts may also be very useful for setting up the databases.
Your configuration will work properly for the following commands (executed from the root of the project):
vagrant up --provider virtualbox: Starts all the VMs.vagrant status: Shows the status for all the VMs.vagrant ssh <vm-name>: Will let you access the VM through SSH.
Manage Your Python applications with PM2
PM2 is a process manager for Node.js applications that makes it easy to manage and scale your application. It is designed to keep your application running continuously, even in the event of an unexpected failure.
PM2 can be used to start, stop, and list Node.js applications, as well as monitor their resource usage and log output.
Additionally, PM2 provides a number of features for managing multiple applications, such as load balancing and automatic restarts.
In our situation we will use it mainly to test resilience for messages sent to the Billing API when the API is not up and running.
After entering in your VM via SSH you may run the following commands:
sudo pm2 list: List all running applications.sudo pm2 stop <app_name>: Stop a specific application.sudo pm2 start <app_name>: Start a specific application.
Project organization
README.md
As a good exercise and a helpful tool it is required for you to deliver a
README.md describing the project.
The idea of a README.md is to give in few lines enough context about a
project to understand what is it about and how to run it.
This file should include instructions to run and test the project, it should also give a brief and clear overview of the stack used to build it.
Overall file structure
You can organize your internal file structure as you prefer. That said here is a common way to structure this kind of projects that may help you:
.
├── README.md
├── config.yaml
├── .env
├── scripts
│ └── [...]
├── srcs
│ ├── api-gateway
│ │ ├── app
│ │ │ ├── __init__.py
│ │ │ └── ... // Other python files
│ │ ├── requirements.txt
│ │ └── server.js
│ ├── billing-app
│ │ ├── app
│ │ │ ├── __init__.py
│ │ │ └── ... // Other python files
│ │ ├── requirements.txt
│ │ └── server.js
│ └── inventory-app
│ │ ├── app
│ │ │ ├── __init__.py
│ │ │ └── ... // Other python files
│ ├── requirements.txt
│ └── server.py
└── Vagrantfile
When testing and before automating it through the VM build you should be able
to start the API Gateway and the two APIs by using the command python server.js inside their respective directories.
As a best practice, you should develop your APIs using separates python virtual
environments to isolate the requirements needed for each API. You can use
venv or any equivalent tool.
If you decide to use a different structure for your project remember you should be able to explain and justify your decision during the audit.
As a best practice it is strongly advised to add
venv/to your.gitignorein order not to upload useless files into your git repository (they will be auto-generated during the build process).